本文关键字: Mask
注意:如果看不到本文图片或者图片未能完全加载,请链接VPN翻墙或者更改HOST文件切换代理。
Mask机制即为掩码机制,其定义为遮罩某些文本元素的方法,该机制在近年来NLP各领域取得了广泛应用,本文将对此机制进行总结与思考。
1、Padding Mask机制
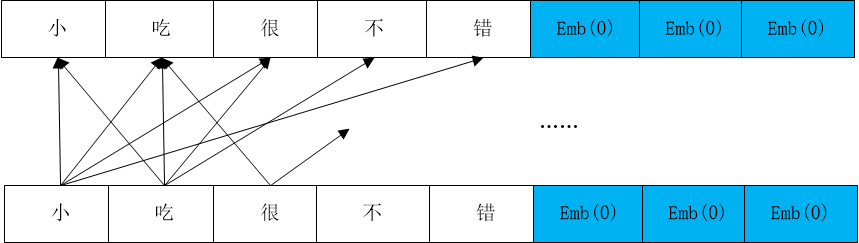
在NLP训练过程中,一般将不同长度的文本句通过补长或者截断处理,将所有句子样本变为长度一致,输入到模型中进行训练。若以”小吃很不错”,
则文本补长过程如下图所示:

在RNN系列变式网络过程中,为了让模型计算过程不再关注后续补零元素,则需要通过Padding Mask机制对文本序列进行处理,去掉句向量中补零位置包含的信息。
首先,Mask矩阵如下所示:

即如上图所示文本序列中,非零元素对应的mask矩阵元素都为1,含0元素为0,则只需要将mask矩阵与原始句向量进行对应相乘,即可去掉原始序列中含零元素的嵌入信息。则在RNN系列模型
的后续计算中,将不会在关注补零部分的元素。
2、Attention机制中的Mask
在NLP领域常见的注意力机制中,Mask应用也十分广泛,尤其在自注意力机制中,亦然如此。自注意力过程如下图所示:
在注意力过程中,key矩阵中每一个Token向量与Query矩阵中每一个Token向量进行相似度匹配,从而得到形状大小为NXN大小的相似度分数矩阵。在该过程中,如果不对句向量进行mask处理
,那么将在下一个步骤通过sofamax计算概率矩阵的过程中,引入含0位置的信息,导致噪音增加。
因此需要引入padding mask机制,将文本序列中补零位置的嵌入元素数值变为-lnf(负无穷大),变为如下图的矩阵后,则通过后面softmax计算概率时,相应元素所得到的概率将为0。此过程也将表示注意力过程
将忽略掉含零位置的信息。

在Multi-head attention机制中,多组self attention并行处理数据。不同self attention分别对应不同的head,具体mask矩阵过程图如下图所示:

则通过加入head mask机制,引入mask矩阵,从而确定最终输出结果包含哪些head信息进行输出。
3、Transformer decoder端中的Mask
在decoder端中,当模型进行target序列预测时,为了避免序列解码过程中受到后面时间步的文本信息影响,则需要加入MASK机制进行遮罩处理,具体如下图所示:

以序列“ABC”为例子,向量[0.8,0.5,0.6,0.5]为该句对应的句向量。当使用自注意力机制时,对于将序列按顺序输入模型的情况,等价于RNN中每一个时间步输入一个字词信息。则若以A词为
例,为了避免匹配过程中受到A后续的分词信息影响,从而需要设置图中三角矩阵进行MASK处理。则即为decoder端MASK机制。
4、语言模型中的Mask
在mask language model中,mask过程如下图所示:

该语言模型,通过将文本中某些Token进行遮罩处理,然后再后续过程中通过遮罩词的上下文,对遮罩词进行预测,从而得到遮罩词的Embedding向量。尤其需要注意的是mask过程需要按照如
下规则进行处理:
1、随机选取样本中15%的Token进行MASK处理。
2、在具体MASK过程中,会从选取15%的Token中,按照80%的比例,用MASK标志替换相应Token;然后按照10%的比例,用一个随机的单词替换对应的Token;最后按照10%的比例,保持原始token不变化。
5、对Mask机制再思考
其实,通过以上实例可以得到一个有效结论,Mask机制可以起到信息筛选作用。鉴于此将Mask机制在注意力机制范畴内进行说法扩充,
描述如下:若存在某文本序列[x1,x2,x3,x4,x5,x6,x7],其中X2,x4为关键词信息,若只想让注意力过程得到这两者信息,该如何操作?答案还是Mask。
如下图所示:

如上图所示,只需要指定所在位置关键词的mask矩阵,从而将非相关元素屏蔽掉,便可在最终计算score矩阵时,通过softmax将非相关词权重设置为0。从而得到含有关键词的x2和x7的权值
矩阵(去掉了其他含0元素)。这也是具体的局部注意力过程。
Mask,彩!







































































